Jul 07, 2021
Cloud Security Term: Infrastructure as Code (IaC)
Within the last 15 years, cloud computing has become a must-have for almost every company developing or using …



One of the more infamous examples of the impact of vulnerable software components is the data breach of the largest consumer credit reporting agency Equifax, back in 2017. The attackers could exploit a vulnerability in the open-source framework Apache Struts2. Although Apache already released a fix for the vulnerability some months before, Equifax did not roll out the update to all servers. This allowed attackers to access their corporate network. By exploiting the vulnerability, the attackers gained access to personal data belonging to Equifax customers, including Social Security numbers, birth dates, and residential addresses of 152 million American, 44 million British, and 8 thousand Canadian residents. The data breach ended up costing Equifax more than 1.7 billion US dollars and the resignation of their Chief Security Officer (CSO) and Chief Information Officer (CIO). Another infamous example is Heartbleed, where a bug in the OpenSSL cryptographic library left a vast number of websites, services, and devices vulnerable. The regular use of software composition analysis (SCA) can inform developers of such vulnerable software components in software projects. In this post, we will introduce SCA, explain how it works, and how it helps to make software more secure.
SCA analyzes the composition of a software project. The objective of this analysis is to identify the open-source dependencies of a software project, check license compliance of the components of this project, and report known security vulnerabilities associated with the identified open-source components.
Open-source libraries have become an indispensable part of any software project. Even most commercial software projects compromise up to 80% of open source code 1, and must be given corresponding attention. As a result, a modern software project can easily contain dozens or hundreds of different open-source components.
One problem that comes immediately to mind is - how does one manage all of these open-source dependencies? There are various solutions available for this problem. Usually, they are programming language-specific. Examples of these tools are Gradle and Maven for Java and NPM for Javascript. Such tools generally automate the process of including open-source software as dependencies. Apart from their primary objective to build the software projects, these tools come with rudimentary features to list and display all the components that compose the software project. However, SCA tools provide more functions than simply listing the used components.
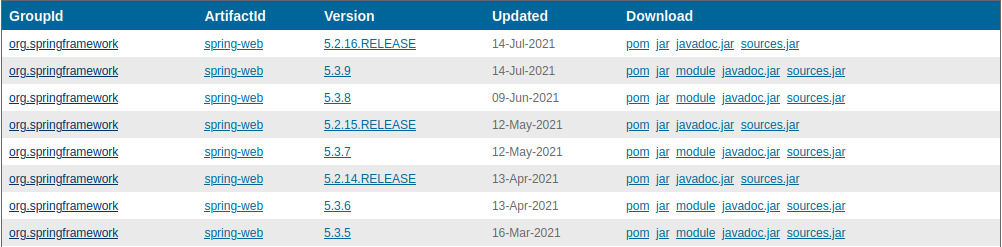
One of the overarching problems SCA tries to solve is identifying the open-source dependencies that are part of the software project. SCA tools typically begin by generating an inventory report for all the third-party open-source components of a project to help with further analysis, e.g., for license checking. An industry-standard way of doing this is the Software Bill Of Materials (SBOM). This is analogous to a Bill Of Materials (BOM) from the manufacturing industry, where it is a list of components and quantities required to manufacture an end product. These components can be direct dependencies, i.e., the ones directly included in the project, and transitive dependencies, i.e., the dependencies required by the direct ones. The SCA tool usually generates this information from the build configuration files that belong to the software project. Such SBOM data structures are used as input to perform various SCA tasks and visualize the dependencies.
<?xml version="1.0" encoding="UTF-8"?>
<bom xmlns="http://cyclonedx.org/schema/bom/1.3"
serialNumber="urn:uuid:3e671687-395b-41f5-a30f-a58921a69b79"
version="1">
<components>
<component type="library">
<name>acme-library</name>
<version>1.0.0</version>
</component>
<!-- More components here -->
</components>
</bom>
Example CycloneDX SBOM - you can see the basic SBOM metadata, and a single component described in the XML file.
Open-source licenses are a legal contract between the maintainers of the open-source project and the user. The Open-Source Initiative has approved around 100 licenses. Some of the more common ones are the Apache License 2.0, BSD 3 Clause, GNU General Public License (GPL), and the MIT license.
When there is a large number of open-source libraries in a projects, there is a higher chance that the project includes licenses that are not as permissive causing legal issues. It can get really difficult to keep track of all licenses. SCA tools can help track license compatibility of known licenses and analyze the SBOM it generated to provide information on which of the used open-source components have incompatible or unknown licenses. For further reading, please refer to the post by David Wheeler [describing license compatibility]https://dwheeler.com/essays/floss-license-slide.html).
This is perhaps the most important directive of SCA. Open-source projects are not bulletproof! While they provide an environment for easy auditing, and thus theoretically allow bugs and malicious code to be caught quicker, security issues do end up falling through the cracks. This means that every open-source component that is part of our software project has the potential of introducing security vulnerabilities. Such vulnerabilities are included in OWASP’s top ten application security risks.
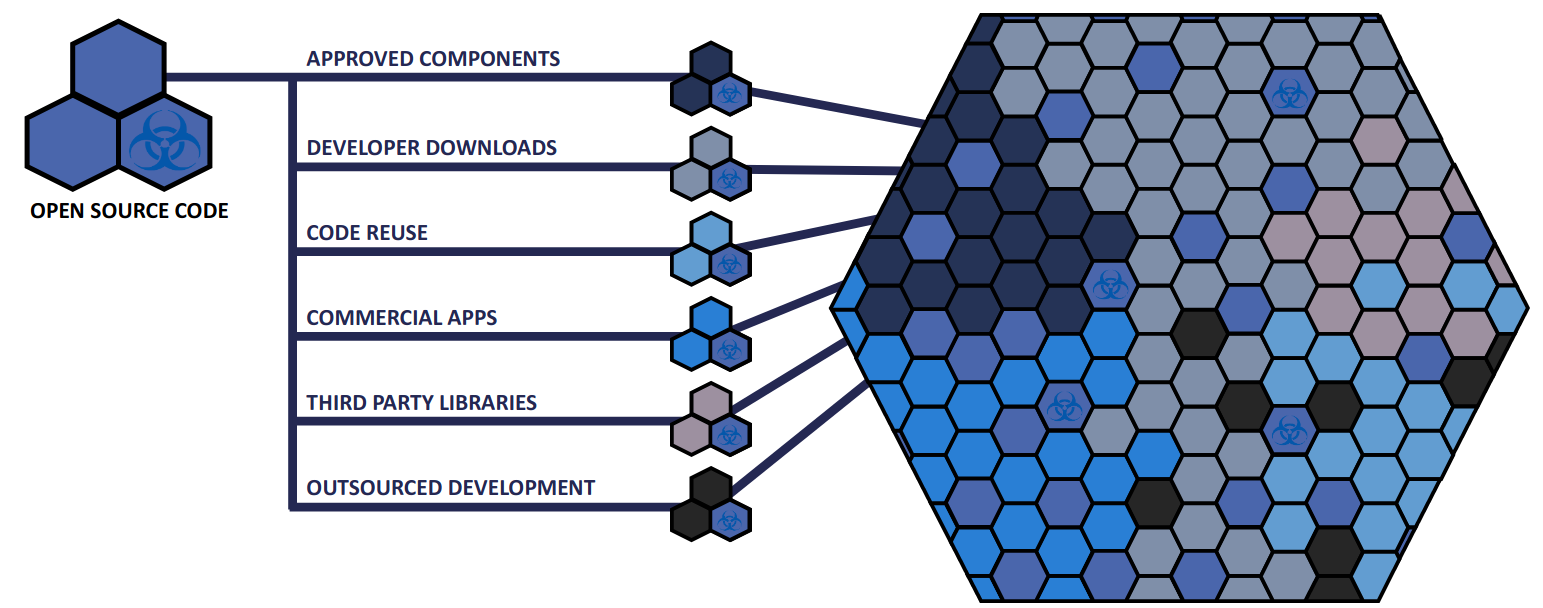
An SCA tool will consume the SBOM generated by itself for a software project and cross-reference each of the dependencies identified against the open-source components found in the vulnerability databases. The tool does this to determine whether there are any know vulnerabilities associated with them. Some of the well known vulnerability databases include GitHub advisories, NPM advisories, the Sonatype OSS index, the common vulnerabilities and exposures (CVE) database and American national vulnerability database (NVD). The problem with using such repositories is that their accuracy in terms of affected artifacts can be suspect. Some further analysis needs to be done to give the user more accurate actionable findings. Identifying this information allows the developers to take remedial action to replace any software components found to be suspicious with a trusted alternative or a version of the software artifact where the vulnerability has been fixed.
Nowadays, the majority of code in our software projects is open-source software. The need to keep track of all open-source components, license compliance issues, and security vulnerabilities led to an increased use of SCA.
Millar, Stuart. “Vulnerability Detection in Open Source Software: The Cure and the Cause.” (2017). ↩︎

Rajiv Thorat is a student assistant at CodeShield.
Within the last 15 years, cloud computing has become a must-have for almost every company developing or using …

In November 2020, an outage of Amazon Web Services (AWS) in the us-east-1 region rendered Roomba vacuum …


Cloud-Native and Serverless applications are trending models for developing cloud applications as they provide …